Speech Analysis with Azure and Go
The last Apple event from November 10th, 2020 inspired me to think about being able to get the most frequently used words automatically from such a well prepared presentation.
By combining different existing tools and services, I should be able to complete this challenge within 1-2 hours of hacking. At least, that was my assumption.
Challenge accepted!
Basic Ingredients
What would be required to get this job done?
- Get the audio from the Youtube video as wav or mp3
- Extract the text from the recorded audio
- Analyse the text and make a simple word histogram
- Filter out words which have no special meaning (e.g. the, or, a, this, …)
- Plot the result as a nice chart
- Interpret the result
So, let’s get started.
Step 1: Extract Audio
In the Linux community, there is a great tool called youtube-dl which allows
to directly extract audio from a Youtube video link. However, the tool
officially was taken down according
to copyright violations. However, there is still the possibility in some Linux
distributions to use the tool extracting the audio.
For the purpose of demonstration, I used the tool, and took care to remove any generated content after the analysis. I also did not redistribute any content.
youtube-dl --extract-audio --audio-format mp3 "https://www.youtube.com/watch?v=5AwdkGKmZ0I"
The extracted result gave me an mp3 audio file which contains just the verbal content, which acts as input for the next step.
Step 2: Extract Text from Audio
Earlier this year I already worked with the Azure Cognitive Vision service, to convert small audio files into text.
The service works pretty well, and is also available for different languages. However, the REST endpoint does not allow to convert audio files with more than 1 minute duration.
There is a different API called batch transcription, which allows to provide a link of an audio file with more than one minute. This service is working asynchronous, and spawns an Azure job in the background.
The next issue is, that the freemium subscription does not allow for batch processing, so I had to create a new standard pricing tier for the cognitive vision service.
That is pretty easy, just create a new resource in your Azure tenant, and you will get your API key within a minute.
While quickly reviewing the API, the tasks are simple:
- Create a transcription
- Query the status of the transcription
- Once being finished, get the result as a JSON file
The swagger documentation of the Azure service is pretty neat, and allows to directly perform the three requests in the browser. However, you may also use Go for performing the requests.
My favorite Go client library for web requests is resty. Easy to use, and pretty simple. Here a simple Go snippet to perform the creation of a transcription.
package main
import (
"encoding/json"
"fmt"
"github.com/go-resty/resty/v2"
)
const (
key = "<your API key>"
baseUrl = "https://<your resource name>.cognitiveservices.azure.com"
path = "/speechtotext/v3.0/transcriptions"
)
type AzureTranscription struct {
ContentUrls []string `json:"contentUrls"`
Properties Properties `json:"properties"`
Locale string `json:"locale"`
DisplayName string `json:"displayName"`
}
type Properties struct {
DiarizationEnabled bool `json:"diarizationEnabled"`
WordLevelTimestampsEnabled bool `json:"wordLevelTimestampsEnabled"`
PunctuationMode string `json:"punctuationMode"`
ProfanityFilterMode string `json:"profanityFilterMode"`
}
func main() {
client := resty.New()
var urls []string
urls = append(urls, "https://yourhost.com/speech.mp3")
props := Properties{
PunctuationMode: "DictatedAndAutomatic",
ProfanityFilterMode: "Masked",
}
job := AzureTranscription{
ContentUrls: urls,
Properties: props,
Locale: "en-US",
DisplayName: "Test speech-to-text",
}
content, _ := json.Marshal(job)
resp, err := client.R().
EnableTrace().
SetHeader("Accept", "application/json").
SetBody(content).
SetHeader("Ocp-Apim-Subscription-Key", key).
Post(baseUrl + path)
if err != nil {
panic(err)
}
fmt.Println(string(resp.Body()))
}
You have to make your sound file publicly available in the internet, or host it in an Azure blob storage.
The response returns the self link of the transaction being spawned, which in
turn can be used to perform a GET request in a similar fashion with resty.
Take care to check the status property. It will switch to Succeeded once the
batch process is done.
In that case, you will get the download link directly in the response of the GET request. This download link points directly to the result file which does not require any authentication with a key anymore. It is a public link. Here is a snippet of the JSON content will is getting returned.
{
"source": "https://yourhost.com/speech.mp3",
"timestamp": "2020-11-10T19:37:41Z",
"durationInTicks": 598400000,
"duration": "PT59.84S",
"combinedRecognizedPhrases": [
{
"channel": 0,
"lexical": "the winter will come in soon",
"itn": "the winter will come in soon",
"maskedITN": "the winter will come in soon",
"display": "The winter will come in soon."
},
{
"channel": 1,
"lexical": "the winter will come in soon",
"itn": "the winter will come in soon",
"maskedITN": "the winter will come in soon",
"display": "The winter will come in soon."
},
],
"recognizedPhrases": [
.....
]
}
You will notice that the service performs the speech to text for both channels in case of a stereo recording. So for optimization purposed, you should convert to mono before creating the process.
The interesting output for our next step is the
combinedRecognizedPhrases[0].lexical field, which already removes all
punctuations.
Step 3: Process Words and Create Histogram
With the result from Azure, we now can take the output, and put it into a simple
Go program in order to count the frequency of used words. With Go, an easy task.
I just manually copied out the text in the lexical field, stored it into a
file, and then extracted the histogram. Of course, you can directly read the
JSON and get the text from there.
The word counts is stored in a map of strings, and can easily be extracted
with the following function:
func wordCount(str string) map[string]int {
wl := strings.Fields(str)
counts := make(map[string]int)
for _, word := range wl {
_, ok := counts[word]
if ok {
counts[word] += 1
} else {
counts[word] = 1
}
}
return counts
}
The map can easily be printed out as a csv file for the next step. Here is a
snippet of the generated file:
1,laura
2,XDR
2,series
17,first
12,get
1,then
3,mind
Step 4: Sorting and Filtering
Before filtering, you can easily sort the csv by using the nice sort command
available under Linux:
sort -n -r words.txt
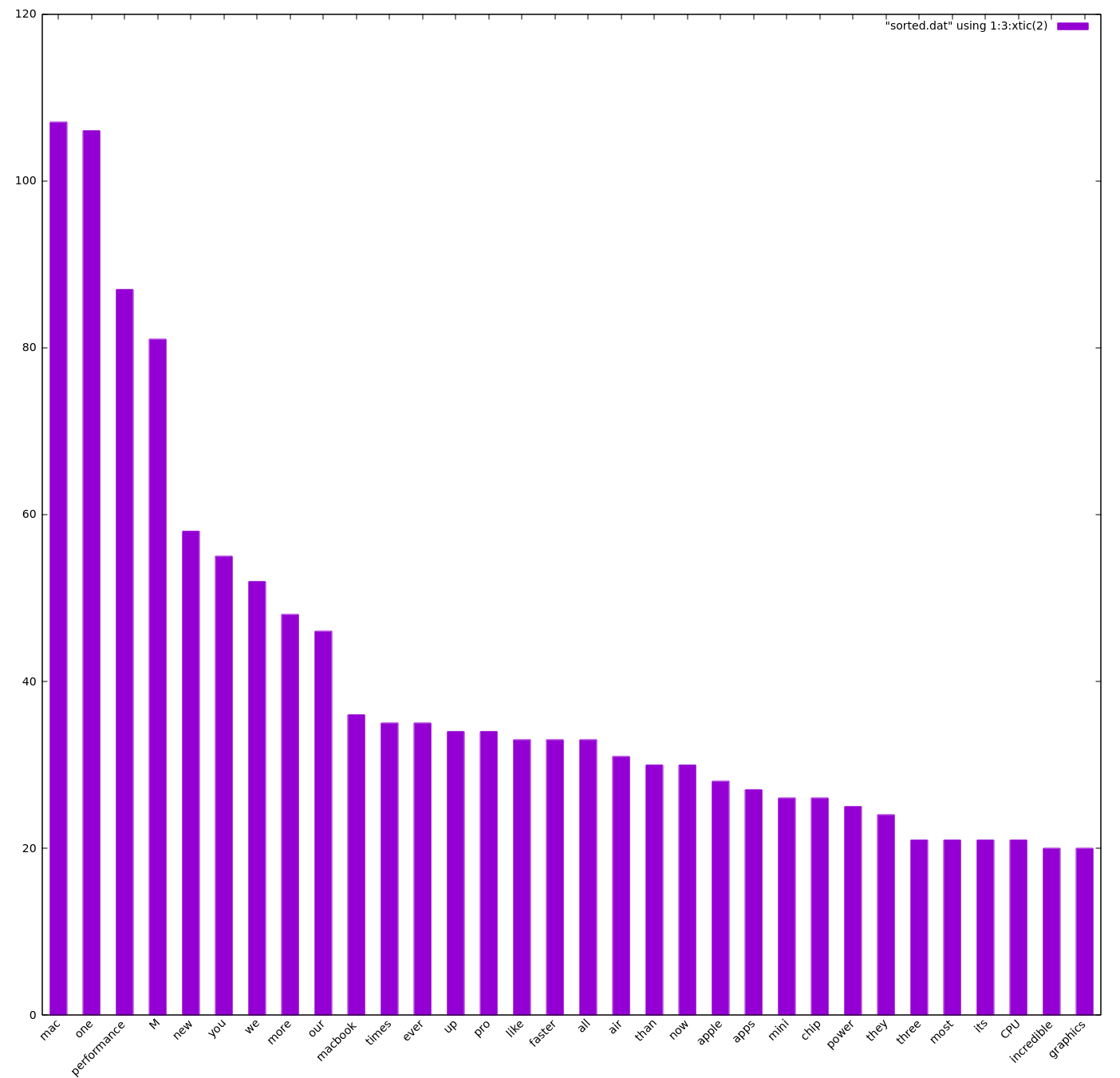
This makes sure that the most frequently used words are on top. The filtering was then done manually with my favorite editor (neovim of course). I also cut of the words with less than 20 counts. That reduced the data items from 1279 to 60, and with the manual filtering down to 32 words. And here is the result of this file
107,mac
106,one
87,performance
81,M
58,new
55,you
52,we
48,more
46,our
36,macbook
35,times
35,ever
34,up
34,pro
33,like
33,faster
33,all
31,air
30,than
30,now
28,apple
27,apps
26,mini
26,chip
25,power
24,they
21,three
21,most
21,its
21,CPU
20,incredible
20,graphics
You may notice the M and one word, which should be taken as one because they
have announced the M1 chip.
Step 5: Interpret the Result
Well, I was surprised how fast it is to get to this information. It took me less than 2 hours to get to this valuable information using simple tools and services and the Go programming language.
Top favorite of the most frequently used words is mac, of course. They have introduced a whole lot of new mac machines with the new processor called M1.
It seems that performance was pretty important for Apple to be repeated all
over again. For a speech of roughly an hour, performance was said more than
once a minute!
Interesting to see that words like you, we, our are also top ranked, which
means that the social factor and community is also pretty important to Apple.
Roughly ever 2nd minute, the company name pops up apple with a count of 28.
Finally, we also want to have a nice graphical plot of this data. Easily done,
of course not with Excel or LibreOffice, but with the good old gnuplot as
follows:
set boxwidth 0.5
set style fill solid
set xtics rotate by 45 right
set yrange[0:120]
plot "data.dat" using 1:3:xtic(2) with boxes
where the data.dat file has to look as follows:
0 mac 107
1 one 106
2 performance 87
And here the final result plotted as a bar chart.